A pretty-printer for TLA+
Table of Contents
I've contributed a TLA+ formatter to the official tlatools. It is also integrated into the VS Code extension. In this article I want to share a few thoughts on what I've learnt along the way about what it takes to write a formatter.
First of all, TLA+ specs are often a work of art. Writing a formatter generic enough to be useful is a daunting task. If you read some of the specs on the Examples repo, you will see inconsistencies even within the same spec. For example, in one section comments are written at the end of the line. In another, they are written on the line above.
The initial version is out and comes with an opinionated (and hopefully helpful) base style. Rather than adding knobs on day 1, the idea is to use feedback to grow the formatter over time and include config options to personalise specific sections differently from the default style.
V0: The rusty version
The very initial version of the formatter was written in Rust and was using the tree-sitter TLA+ grammar for the lexer. This was fine for a PoC; however, the official TLA+ parser is SANY and it is written in Java. To get the official tooling support, I quickly decided to abandon my Rust formatter and adopt Java instead.
Quick tour of SANY API
SANY (short for Syntactic ANalYzer) produces as output the AST (Abstract Syntax Tree) of the parsed spec. In order to generate the AST, the spec must be syntactically valid to be formatted.
Assume this spec:
---- MODULE SimpleTest ----
VARIABLE x
Init == x = 0
====
Once we call SANYWrapper.load() we get a TreeNode object that looks like this:
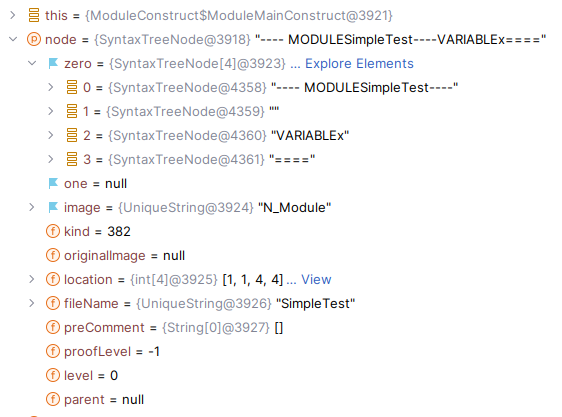
zero and one are usually used to store arguments of the node. kind is the unique node kind id. image is either the human-friendly name (N_Module) or the value (from the example above, "SimpleTest" for the identifier kind).
The full list of kinds is available in the tlaplus source here.
You can see there is also information about levels in there, though for a formatter all I needed was the tree structure with the attached values.
V1: The wrong way
Given my familiarity with ASTs was mostly related to writing interpreters, my thought process was to first visit the root node and then print the label and/or recursively print its inner parts.
Reusing the spec above as an example, for printing the header:
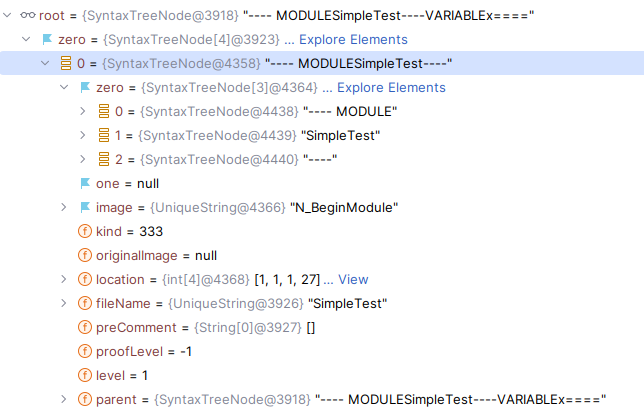
- A generic dispatch function resolves to a class that knows how to format
N_BeginModuleby using thekindid. - This class recursively calls the generic dispatch function on each child node.
- The format function is called on each child.
I was able to quickly put a formatter together this way. I had the list of possible node kinds from SANY source and, after adding enough of them, the formatter was mostly working. But the problem with this approach became quite obvious quite fast.
When you produce the output this way, there's no backtracking. Therefore, what you produce doesn't take into consideration the size of the screen of the user, nor what the child tree contains.
For example, in TLA+ there are if-then-else (ITE) logical branching constructs. A short formula could look like this:
IF TRUE THEN 1 ELSE 0
The expr inside the bodies might get much longer than this. In that case, the right approach would be to break the keywords:
IF <very-long-expr>
THEN 1
ELSE 0
But let's say that this appears on the right side of an operator with a short name. In that case, it might still be fine to inline everything:
T == IF <very-long-expr> THEN 1 ELSE 0
Depending on the user's screen, or in other words the configured column limit, this might fit in a single line. If you think about it, given a small enough screen size even the first trivial ITE example would break into multiple lines.
For this reason, I decided to throw away the first version and start from scratch.
One resource that was very helpful and also described the above problem was "The Hardest Program I've Ever Written" (not very encouraging, is it?). Other than that, I couldn't find many resources online. I assumed it was because, well, there aren't many formatters (not every language really cares much about having one) or maybe because... it was a solved problem?
V2: Pretty printer Wadler-style
The most influential work was the 1998 paper "A Prettier Printer" by P. Wadler. It presents a list of combinators and a functional-style implementation of work from D. Oppen's 1980 paper "Pretty Printing". While both algorithms are optimal and bounded, Wadler explains that implementing Oppen's algorithm due to its use of the buffer can be tricky.
That's why usually (as far as I can tell) pretty printers are derived from Wadler's paper. After that, not many papers on this topic were produced. Most of them are about alternative implementations. For example, there is an interesting one by Lindig that doesn't need to exploit Haskell's laziness to be optimal, making it easier to implement in other languages that don't come with this evaluation semantic.
Of course, after I learnt about this I didn't want to write a library for pretty printers but would have rather just used something off-the-shelf. That's how I landed on a Java implementation called prettier4j by David Gregory from OpenCast:
A Java implementation of Philip Wadler's "A prettier printer", a pretty-printing algorithm for laying out hierarchical documents as text.
The interface is quite easy to use and it is directly derived from the paper — plus additional super useful combinators to improve the developer experience.
This is what the ITE definition looks like:
var indentIfSize = "IF".length();
Doc ifKey = context.buildChild(node.zero()[0]);
Doc condition = Doc.group(context.buildChild(node.zero()[1])).indent(indentIfSize);
Doc thenKey = context.buildChild(node.zero()[2]);
Doc thenExpr = Doc.group(context.buildChild(node.zero()[3])).indent(indentIfSize);
Doc elseKey = context.buildChild(node.zero()[4]);
Doc elseExpr = Doc.group(context.buildChild(node.zero()[5])).indent(indentIfSize);
return Doc.group(ifKey.appendSpace(condition)
.appendLineOrSpace(thenKey.appendSpace(thenExpr)
.appendLineOrSpace(elseKey.appendSpace(elseExpr))));
Quite readable and easy to follow, don't you think?
The basic idea is that we pass to prettier4j an intermediate representation of the output. As opposed to what my initial version was doing, the decision of whether to break a line is deferred until render time: the printer can measure the intermediate representation and decide if the output will fit the configured line length. If it won't, it will keep breaking groups and their subgroups until everything fits within the line.
And with that, the second version of the formatter came out and it is working much better than the previous one.
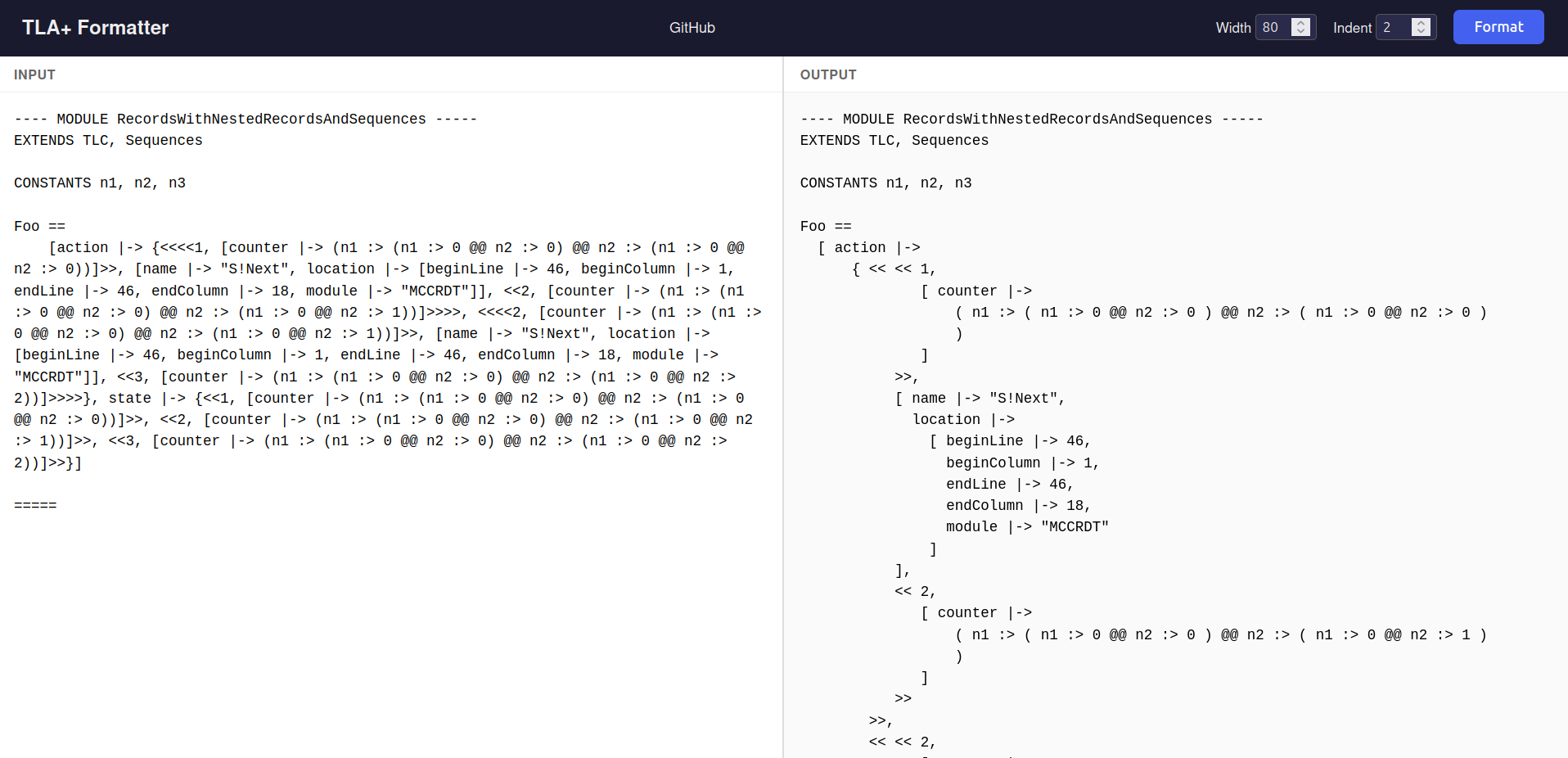
With the formatter working, the next challenge was proving it correct at scale.
Testing strategy: generator or corpus
Most of the tests for the formatter are similar to Snapshot Testing, where you have an input, an output generated from a past run, and the test asserts the output is still generated by the input.
The options here are to either generate specs programmatically or take a large corpus of examples and format those. Of course, there are also tests that aim to verify the rendering of specific constructs, but they are usually rather small.
The spec generation idea was particularly interesting to me. Ideally, the generator could be reused for other tooling too, I thought, so it would be nice to have it.
The EBNF (Extended Backus–Naur form) grammar for TLA+ is available here. But an EBNF defines only the grammar of a language. For example, you wouldn't get a syntax error for "1+x" as it is syntactically correct, but it would be semantically incorrect if x is undefined in the environment used for the evaluation.
Looking around, this kind of tool is not available for many languages. I found Csmith to be a nice project for generating valid C programs:
Csmith is a random generator of C programs. Its primary purpose is to find compiler bugs with random programs, using differential testing as the test oracle. Csmith outputs C programs free of undefined behaviors (believe us, that's not trivial), and the statistics of each generated program.
I tried to put together a PoC using an LLM for a program called tlaplus-smith. A simple usage is:
import me.fponzi.tlasmith.TLASmith;
import me.fponzi.tlasmith.ast.Spec;
import me.fponzi.tlasmith.validation.SanyValidator;
// Generate a random TLA+ specification
Spec spec = TLASmith.generateSpec("MyModule");
// Generate with seed for reproducibility
Spec spec = TLASmith.generateSpec("MyModule", 12345);
// Validate with SANY
SanyValidator.ValidationResult result = TLASmith.validate(spec);
System.out.println("Generated spec validation: " + result.isValid());
Writing this program is a large effort on its own. While fun and interesting, it was delaying the initial release of the formatter. For this reason, I decided to put it to the side and fall back to the corpus. But where to find a large enough corpus?
Corpus
TLA+ comes with an extensive Examples repo which I used as a test Corpus. Once I got to a satisfying version of the formatter, validating it against the corpus helped iron out missing node handling and a few edge cases. The validation consists of formatting all specs found in the Examples repo and verifying that their AST matches the initial version. This validation is now part of the test suite and gets run on every merge to master.
If I hadn't had access to this repo, I would have had to do some scraping myself. So having an Examples repo for your language can have secondary benefits as well.
A formatter that can be trusted
Two interesting properties for a formatter are:
- The formatter must be idempotent. Formatting the output of a formatter run should not result in any change.
- The formatter must never modify the AST.
A formatter's job is to add or remove whitespace and newlines. These two tokens are ignored in the AST.
However, there is a massive difference between a formatting error that breaks a spec by causing a syntax error and one that silently alters its semantics. Especially in TLA+, a semantic shift would be catastrophic. In TLA+ indentation can literally change the logic, think about a block of nested /\ or / conjunctions/disjunctions.
For this reason, the formatter comes with an option (enabled by default) to verify the AST of the reformatted spec. It parses the code both before and after formatting, then compares the two trees. If they don't match, the formatter loudly fails. Lose some speed to gain peace of mind!
Usage

The formatter is now part of tlatools and can be invoked from the command line:
java -cp tla2tools.jar formatter.Main [OPTIONS] <FILE> [OUTFILE]
Options:
-i, --indent <N> Indentation spaces (default: 4)
-w, --width <N> Target line width (default: 80)
-v, --verbosity <LEVEL> ERROR, WARN, INFO, DEBUG
--skip-ast-verification Skip AST verification after formatting
-h, --help Show help message and exit
Conclusion
TLA+ has a formatter now. It ships with AST verification enabled by default, supports configurable indentation and line width, and is integrated into both the CLI tooling and the VS Code extension. I'm happy with how it turned out. Please give it a try and let me know if you like it and if you have any feedback!
If you have some background in writing pretty-printers, I'd love to hear your thoughts on it as well.
There is room for future work. TLA+ can also be written using the PlusCal language, and that is not supported by the formatter yet. Adding basic support for it would mean almost writing a new formatter from scratch. For the TLA+ language a single style is currently available. Support for a config and personalized styles could be quickly put together as soon as different users come with requests that deviate from the default style. tlaplus-smith remains a PoC, but I think it would be a valuable additional tool in the long run. Given that the target audience is limited to those developing TLA+ tooling, the userbase remains small. Still, it would be a fun project to undertake.
Resources
- TLA+ formatter source: https://github.com/tlaplus/tlaplus/tree/master/tlatools/org.lamport.tlatools/src/formatter
- P. Wadler (2003; first circulated 1998). A prettier printer. The Fun of Programming.
- D. C. Oppen (1980), "Pretty-printing", ACM Trans. Program. Lang. Syst.
- "Prettier" formatter design
- Bob Nystrom (2015), "The Hardest Program I've Ever Written"
- prettier4j by OpenCast: https://github.com/opencastsoftware/prettier4j
- TLA+ EBNF (JavaCC grammar): https://github.com/tlaplus/tlaplus/blob/6932e19083fc6df42473464857fc1280cb5aaecc/tlatools/org.lamport.tlatools/javacc/tla%2B.jj
- Miguel Young de la Sota (2025) "The art of formatting code". Very recent article, not quoted in here but I think it's a nice follow-up read.
